
[케라스(keras) 이해] 8장. 생성 모델을 위한 딥러닝
 본 글은 [케라스 창시자에게 배우는 딥러닝] - (박해선 옮김) 책을 개인공부하기 위해 요약, 정리한 내용입니다.
본 글은 [케라스 창시자에게 배우는 딥러닝] - (박해선 옮김) 책을 개인공부하기 위해 요약, 정리한 내용입니다.
전체 코드는 https://github.com/ingu627/deep-learning-with-python-notebooks에 기재했습니다.(원본 코드 fork)
뿐만 아니라 책에서 설명이 부족하거나 이해가 안 되는 것들은 외부 자료들을 토대로 메꿔 놓았습니다. 즉, 딥러닝은 이걸로 끝을 내보는 겁니다.
오타나 오류는 알려주시길 바라며, 도움이 되길 바랍니다.
8.1 LSTM으로 텍스트 생성하기
- 순환 신경망으로 시퀀시 데이터를 생성하는 방법을 알아본다.
8.1.2 시퀀스 데이터를 어떻게 생성할까?
- 딥러닝에서 시퀀스 데이터를 생성하는 일반적인 방법은 이전 토큰을 입력으로 사용해서 시퀀스의 다음 1개 또는 몇 개의 토큰을 예측.
- 언어 모델(language model) : 이전 토큰들이 주어졌을 때 다음 토큰의 확률을 모델링할 수 있는 네트워크
- 과정
- 언어 모델은 언어의 통계적 구조인 잠재 공간을 탐색한다.
- 언어 모델 훈련 후 이 모델에서 샘플링 가능 (새로운 시퀀스 생성)
- 초기 텍스트 문자열을 주입(= 조건 데이터)학고 새로운 글자나 단어를 생성한다.
- 생성된 출력은 다시 입력 데이터로 추가된다.
- 이 과정을 여러 번 반복한다.

8.1.3 샘플링 전략의 중요성
- 텍스트를 생성할 때 다음 글자를 선택하는 방법들이 있다.
- 탐욕적 샘플링(greedy sampling) : 항상 가장 높은 확률을 가진 글자를 선택
- 확률적 샘플링(stochastic sampling) : 다음 글자의 확률 분포에서 샘플링하는 과정에 무작위성을 주입하는 방법
8.1.4 글자 수준의 LSTM 텍스트 생성 모델 구현
- 19세기 후반 독일의 철학자 니체의 글을 예시를 이용해서 케라스로 구현해보기
데이터 전처리
- 원본 텍스트 파일을 내려받아 파싱하기
from tensorflow.keras import utils
import numpy as np
path = utils.get_file(
'nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open(path).read().lower() # 말물칭를 내려받아 소문자로 바꿔준다.
print('말뭉치 크기:', len(text))
# Downloading data from https://s3.amazonaws.com/text-datasets/nietzsche.txt
# 606208/600901 [==============================] - 1s 2us/step
# 말뭉치 크기: 600893
- 글자 시퀀스 벡터화하기
maxlen = 60 # 60개의 글자로 된 시퀀스 추출
step = 3 # 세 글자씩 건너뛰면서 새로운 시퀀스를 샘플링한다.
sentences = [] # 추출한 시퀀스를 담을 리스트
next_chars = [] # 타깃(시퀀스 다음 글자)을 담을 리스트
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('시퀀스 개수:', len(sentences)) # 200278
chars = sorted(list(set(text))) # 말뭉치에서 고유한 글자를 담은 리스트
print('고유한 글자:', len(chars)) # 58
char_indices = dict((char, char.index(char)) for char in chars) # chars 리스트에 있는 글자와 글자의 인덱스를 매핑한 딕셔너리
print('벡터화...')
# 글자를 원핫 인코딩하여 0과 1의 이진 배열로 바꿔준다.
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
- 이 문서에서 숫자와 구두점 등을 포함하여 고유한 글자의 수는 57개이다.
- 만들어진 훈련 데이터 x의 크기는 (200278, 60, 57)이고 y의 크기는 (200278, 57)이다.
네트워크 구성
- 다음 글자를 예측하기 위한 단일 LSTM 모델
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
model.add(Dense(len(chars), activation='softmax'))
- 모델 컴파일 설정하기
from tensorflow.keras.optimizers import RMSprop
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
언어 모델 훈련과 샘플링
- 훈련된 모델과 시드로 쓰일 간단한 텍스트가 주어지면 다음과 같이 반복하여 새로운 텍스트를 생성한다.
- 지금까지 생성된 텍스트를 주입하여 모델에서 다음 글자에 대한 확률 분포를 뽑는다.
- 특정 온도로 이 확률 분포의 가중치를 조정한다.
- 가중치가 조정된 분포에서 무작위로 새로운 글자를 샘플링한다.
- 새로운 글자를 생성된 텍스트의 끝에 추가한다.
- 모델의 예측이 주어졌을 때 새로운 글자를 샘플링하는 함수
import numpy as np
def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
- 텍스트 생성 루프
import random
import sys
random.seed(42)
start_index = random.randint(0, len(text) - maxlen - 1)
for epoch in range(1, 60): # 60 에포크 동안 모델 훈련
print('에포크', epoch)
model.fit(x, y, batch_size=128, epochs=1) # 데이터에서 한 번만 반복해서 모델 학습
seed_text = text[start_index: start_index + maxlen] # 무작위로 시드 텍스트를 선택한다.
print('--- 시드 텍스트: "' + seed_text + '"')
for temperature in [0.2, 0.5, 1.0, 1.2]: # 여러 가지 샘플링 온도를 시도
print('------ 온도:', temperature)
generated_text = seed_text
sys.stdout.write(generated_text)
for i in range(400): # 시드 텍스트에서 시작해서 400개의 글자를 생성한다.
# 원 핫 인코딩으로 바꿈
sampled = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(generated_text):
sampled[0, t, char_indices[char]] = 1.
# 다음 글자를 샘플링
preds = model.predict(sampled, verbose=0)[0]
next_index = sample(preds, temperature)
next_char = chars[next_index]
generated_text += next_char
generated_text = generated_text[1:]
sys.stdout.write(next_char)
sys.stdout.flush()
print()
8.2. 딥드림
- 딥드림(DeepDream) = 합성곱 신경망이 학습한 표현을 사용하여 예술적으로 이미지를 조작하는 기법
- 딥드림 알고리즘은 컨브넷을 거꾸로 실행하는 컨브넷 필터 시각화 기법과 거의 동일하다.
- 특징
- 딥드림에서는 특정 필터가 아니라 전체 층의 활성화를 최대화한다. 한꺼번에 많은 특성을 섞어 시각화한다.
- 빈 이미지나 노이즈가 조금 있는 입력이 아니라 이미 가지고 있는 이미지를 사용한다.
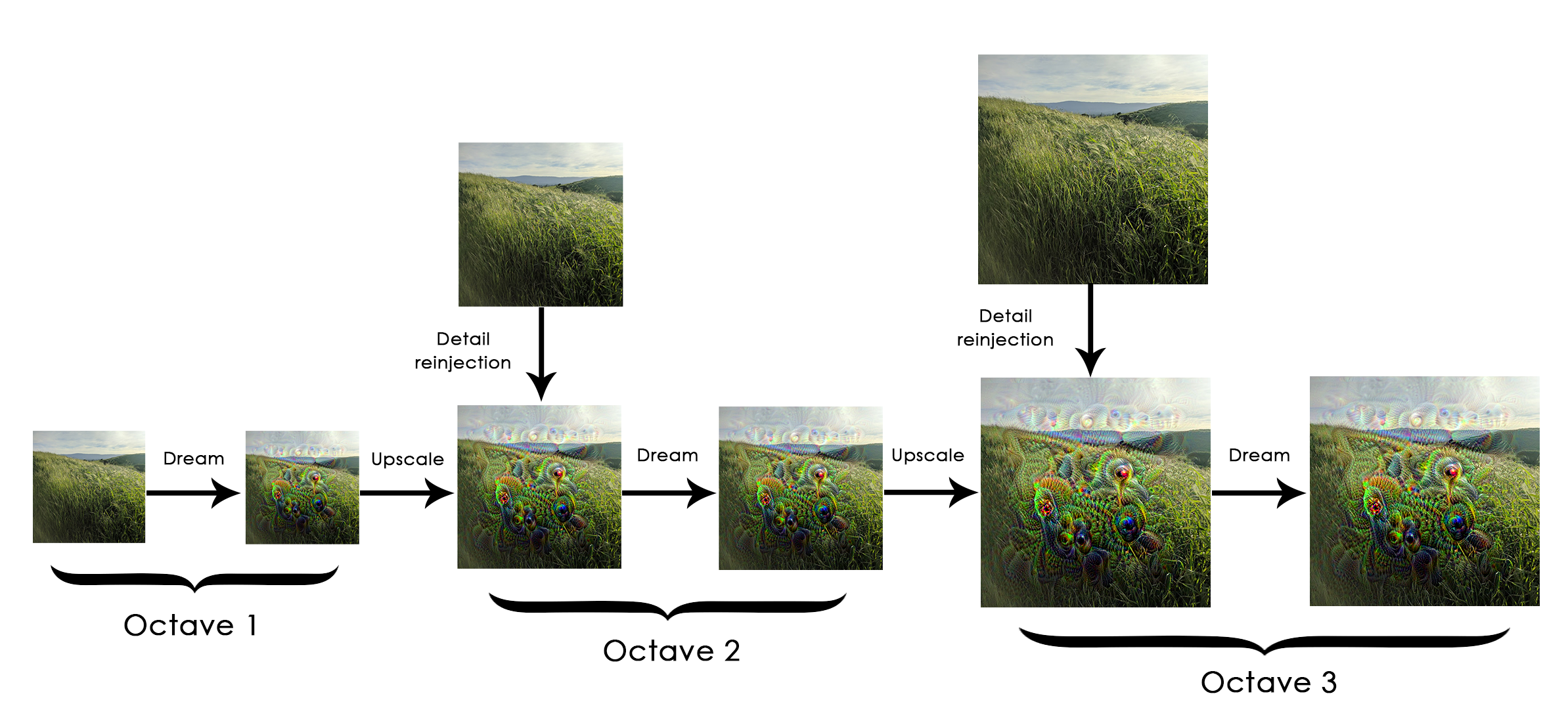
- 입력 이미지는 시각 품질을 높이기 위해 여러 다른 스케일(=옥타브(octave))로 처리한다.
- 옥타브 : 이미지 크기를 일정한 비율로 연속적으로 줄이거나 늘리는 방식
-> 딥드림 과정 : 연속적으로 스케일을 늘리고(옥타브), 스케일이 증가된 이미지에 디테일을 재주입
8.2.1 케라스 딥드림 구현
- 사전 훈련된 인셉션 V3 모델 로드하기
from tensorflow.keras.applications import inception_v3
from tensorflow.keras import backend as K
K.set_learning_phase(0) # 모델 훈련 연산을 비활성화
model = inception_v3.InceptionV3(weights='imagenet',
include_top=False)
- 딥드림 설정하기
- 최대화하려는 손실에 층의 활성화가 기여할 양을 정한다.
- 층 이름은 내장된 인셉션 V3 애플리케이션에 하드코딩되어 있는 것
layer_contributions = {
'mixed2': 0.2,
'mixed3': 3.,
'mixed4': 2.,
'mixed5': 1.5,
}
- 최대화할 손실 정의하기
layer_dict = dict([(layer.name, layer) for layer in model.layers])
loss = K.variable(0.) # 손실을 정의하고 각 층의 기여 분을 이 스칼라 변수에 추가
for layer_name in layer_contributions:
coeff = layer_contributions[layer_name]
activation = layer_dict[layer_name].output # 층의 출력을 얻는다.
scaling = K.prod(K.cast(K.shape(activation), 'float32'))
loss = loss + coeff * K.sum(K.square(activation[:, 2: -2, 2: -2, :])) / scaling # 층 특성의 L2 노름 제곱을 손실에 추가한다.
- 경사 상승법 과정
import tensorflow as tf
dream = model.input # 생성된 딥드림 이미지 저장
grads = K.gradients(loss, dream)[0] # 손실에 대한 딥드림 이미지의 그래디언트를 계산
grads /= K.maximum(K.mean(K.abs(grads)), 1e-7) # 그래디언트 정규화
outputs = [loss, grads]
fetch_loss_and_grads = K.function([dream], outputs)
def eval_loss_and_grads(x):
outs = fetch_loss_and_grads([x])
loss_value = outs[0]
grad_values = outs[1]
return loss_value, grad_values
# 이 함수는 경사 상승법을 여러 번 반복하여 수행한다.
def gradient_ascent(x, iterations, step, max_loss=None):
for i in range(iterations):
loss_value, grad_values = eval_loss_and_grads(x)
if max_loss is not None and loss_value > max_loss:
break
print('...', i, '번째 손실 :', loss_value)
return x
- 딥드림 과정
- 유틸리티 함수
import scipy
from tensorflow.keras.preprocessing import image
def resize_img(img, size):
img = np.copy(img)
factors = (1,
float(size[0]) / img.shape[1],
float(size[1]) / img.shape[2],
1)
return scipy.ndimage.zoom(img, factors, order=1)
def save_img(img, fname):
pil_img = deprocess_image(np.copy(img))
image.save_img(fname, pil_img)
def preprocess_image(image_path): # 사진을 열고 크기를 줄이고 인셉션 V3가 인식하는 텐서 포맷으로 변환하는 유틸리티 함수
img = image.load_img(image_path)
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = inception_v3.preprocess_input(img)
return img
def deprocess_image(x): # 넘파일 배열을 적절한 이미지 포맷으로 변환하는 유틸리티 함수
if K.image_data_format() == 'channels_first':
x = x.reshape((3, x.shape[2], x.shape[3]))
x = x.transpose((1, 2, 0))
else:
x = x.reshape((x.shape[1], x.shape[2], 3))
x /= 2.
x += 0.5
x *= 255.
x = np.clip(x, 0, 255).astype('uint8')
return x
- 연속적인 스케일에 걸쳐 경사 상승법 실행하기
import numpy as np
step = 0.01 # 경사 상승법 단계 크기
num_octave = 3 # 경사 상승법을 실행할 스케일 단계 횟수
octave_scale = 1.4 # 스케일 간의 크기 비율
iterations = 20 # 스케일 단계마다 수행할 경사 상승법 횟수
max_loss = 10. # 손실이 10보다 커지면 이상한 그림이 되기 때문에 경사 상승법 과정을 중지한다.
base_image_path = '../datasets/original_photo_deep_dream.jpg' # 사용할 이미지 경로
img = preprocess_image(base_image_path) # 기본 이미지를 넘파이 배열로 로드
original_shape = img.shape[1:3]
successive_shapes = [original_shape] # 경사 상승법을 실행할 스케일 크기를 정의한 튜플의 리스트를 준비
for i in range(1, num_octave):
shape = tuple([int(dim / (octave_scale ** i)) for dim in original_shape])
successive_shapes.append(shape)
successive_shapes = successive_shapes[::-1] # 리스트를 크기 순으로 뒤집는다.
original_img = np.copy(img)
shrunk_original_img = resize_img(img, successive_shapes[0]) # 이미지의 넘파이 배열을 가장 작은 스케일로 변경한다.
for shape in successive_shapes:
print('처리할 이미지 크기', shape)
img = resize_img(img, shape)
img = gradient_ascent(img,
iterations=iterations,
step=step,
max_loss=max_loss)
upscaled_shrunk_original_img = resize_img(shrunk_original_img, shape) # 작게 줄인 원본 이미지의 스케일을 높인다. (픽셀 경계가 보일 것이다.)
same_size_original = resize_img(original_img, shape) # 이 크기에 해당하는 원본 이미지의 고해상도 버전을 계산한다.
lost_detail = same_size_original - upscaled_shrunk_original_img # 이 두 이미지의 차이가 스케일을 높였을 때 손실된 디테일
img += lost_detail # 손실된 디테일을 딥드림 이미지에 다시 주입
shrunk_original_img = resize_img(original_img, shape)
save_img(img, fname='dream_at_scale_' + str(shape) + '.png')
save_img(img, fname='../datasets/final_dream.png')
위 코드에서 에러 발생
RuntimeError: tf.gradients is not supported when eager execution is enabled. Use tf.GradientTape instead.
2022.01.27 에러 해결 $\rightarrow$ https://ingu627.github.io/error/tfgradients/
8.3 뉴럴 스타일 트랜스퍼

- 뉴럴 스타일 트랜스퍼 (neural style transfer) : 딥러닝을 사용하여 이미지를 변경하는 방법
- 스타일 : 질감, 색깔, 이미지에 있는 다양한 크기의 시각 요소를 의미
- 콘텐츠 : 이미지에 있는 고수준의 대형 구조
8.3.1 콘텐츠 손실
- 네트워크에 있는 하위 층의 활성화는 이미지에 관한 국부적인 정보를 담고 있다.
- 컨브넷 층의 활성화는 이미지를 다른 크기의 콘텐츠로 분해한다.
- 하지만 상위 층의 활성화일수록 점점 전역적이고 추상적인 정보를 담고 있다.
- 컨브넷 상위 층의 표현을 사용하면 전역적이고 추상적인 이미지 콘텐츠를 찾는다.
- 딥러닝 알고리즘의 핵심은 목표를 표현한 손실 함수를 정의하고 이 손실을 최소화한다. $\rightarrow$ 참조 이미지의 스타일을 적용하면서 원본 이미지의 콘텐츠를 보존하는 것이다.
loss(손실함수) = distance(style(reference_image) - style(generated_image)) +
distance(content(original_image) - content(generated_image)) # distance는 노름 함수
- 방법으론 타깃 이미지와 생성된 이미지를 사전 훈련된 컨브넷에 주입하여 상위 층의 활성화를 계산한다.
- 이 두 값 사이의 L2 노름을 콘텐츠 손실로 사용한다.
8.3.2 스타일 손실
- 콘텐츠 손실은 하나의 상위 층만 사용한다.
- 게티스 등은 층의 활성 출력의 그람 행렬 (Gram matrix)을 스타일 손실로 사용했다. $\nearrow$ (그람 행렬은) 층의 특성 맵들의 내적이다.
- 내적은 층의 특성 사이에 있는 상관관계를 표현한다고 이해할 수 있다.
- 손실 정의
- 콘텐츠를 보존하기 위해서 타깃 콘텐츠 이미지와 생성된 이미지 사이에서 상위 층의 활성화를 비슷하게 유지한다.
- 스타일을 보존하기 위해 저수준 층과 고수준 층에서 활성화 안에 상관관계를 비슷하게 유지한다.
8.3.3 케라스에서 뉴럴 스타일 트랜스퍼 구현하기
- 일반적인 과정
- 스타일 참조 이미지, 타깃 이미지, 생성된 이미지를 위해 VGG19의 층 활성화를 동시에 계산하는 네트워크를 설정
- 세 이미지에서 계산한 층 활성화를 사용하여 앞서 설명한 손실 함수를 정의한다. 이 손실을 최소화하여 스타일 트랜스퍼를 구현
- 손실 함수를 최소화할 경사 하강법 과정을 설정
- 변수 초깃값 정의하기
from tensorflow.keras.preprocessing.image import load_img, img_to_array, save_img
target_image_path = '../datasets/portrait.png' # 변환하려는 이미지 경로
style_reference_image_path = '../datasets/popova.jpg' # 스타일 이미지 경로
# 생성된 사진의 차원
width, height = load_img(target_image_path).size
img_height = 400
img_width = int(width * img_height / height)
- 유틸리티 함수
import numpy as np
from tensorflow.keras.applications import vgg19
def preprocess_image(image_path):
img = load_img(image_path, target_size=(img_height, img_width))
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return img
def deprocess_image(x):
# ImageNet의 평균 픽셀 값 더함
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB'
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
- 사전 훈련된 VGG19 네트워크를 로딩하고 3개 이미지에 적용하기
from tensorflow.keras import backend as K
target_image = K.constant(preprocess_image(target_image_path))
style_reference_image = K.constant(preprocess_image(style_reference_image_path))
# 생성된 이미지를 담을 플레이스홀더
combination_image = K.placeholder((1, img_height, img_width, 3))
input_tensor = K.concatenate([target_image,
style_reference_image,
combination_image], axis=0)
# 세 이미지의 배치를 입력으로 받는 VGG 네트워크를 만든다.
# 이 모델은 사전 훈련된 ImageNet 가중치를 로드한다.
model = vgg19.VGG19(input_tensor=input_tensor,
weights='imagenet',
include_top=False)
- 콘텐츠 손실
def content_loss(base, combination):
return K.sum(K.square(combination - base))
- 스타일 손실
def gram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram = K.dot(features, K.transpose(features))
return gram
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_height * img_width
return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
- 총 변위 손실 (variation loss) : 생성된 이미지의 픽셀을 사용하여 계산
- 생성된 이미지가 공간적인 연속성을 가지도록 도와주며 픽셀의 격자 무늬가 과도하게 나타나는 것을 막아준다.
def total_variation_loss(x):
a = K.square(
x[:, :img_height -1, :img_width - 1, :] -
x[:, 1:, :img_width - 1, :])
b = K.square(
x[:, :img_height - 1, :img_width - 1, :] -
x[:, :img_height - 1, 1:, :])
return K.sum(K.pow(a + b, 1.25))
- 최소화할 최종 손실 정의하기
- 최소화할 손실은 이 세 손실의 가중치 평균이다.
# 층 이름과 활성화 텐서를 매핑한 딕셔너리
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
content_layer = 'block5_conv2'
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1',]
total_variation_weight = 1e-4
style_weight = 1.
content_weight = 0.025
loss = K.variable(0.) # 모든 손실 요소를 더하여 하나의 스칼라 변수로 손실을 정의한다.
# 콘텐츠 손실 더하기
layer_features = outputs_dict[content_layer]
target_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss = loss + content_weight * content_loss(target_image_features,
combination_features)
# 각 타깃 층에 대한 스타일 손실 더함
for layer_name in style_layers:
layer_features = outputs_dict[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_reference_features, combination_features)
loss += (style_weight / len(style_layers)) * sl
loss = loss + total_variation_weight * total_variation_loss(combination_image)
- 경사 하강법 단계 설정하기
# 손실에 대한 생성된 이미지의 그래디언트를 구한다.
grads = K.gradients(loss, combination_image)[0]
# 현재 손실과 그래디언트 값을 추출하는 케라스 Function 객체이다.
fetch_loss_and_grads = K.function([combination_image], [loss, grads])
class Evaluator(object):
def __init__(self):
self.loss_value = None
self.grads_values = None
def loss(self, x):
assert self.loss_value is None
x = x.reshape((1, img_height, img_width, 3))
outs = fetch_loss_and_grads([x])
loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
evaluator = Evaluator()
위 코드에서 에러 발생
RuntimeError: tf.gradients is not supported when eager execution is enabled. Use tf.GradientTape instead.
2022.01.27 에러 해결 $\rightarrow$ https://ingu627.github.io/error/tfgradients/
- 스타일 트랜스퍼 반복 루프
from scipy.optimize import fmin_l_bfgs_b
import time
result_prefix = 'style_transfer_result'
iterations = 20
x = preprocess_image(target_image_path)
x = x.flatten()
for i in range(iterations):
print('반복 횟수:', i)
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss,
x,
fprime=evaluator.grads,
maxfun=20)
print('현재 손실 값:', min_val)
img = x.copy().reshape((img_height, img_width, 3))
img = deprocess_image(img)
fname = result_prefix + '_at_iteration_%d.png' % i
save_img(fname, img)
print('저장 이미지: ', fname)
end_time = time.time()
print('%d 번째 반복 완료: %ds' % (i, end_time - start_time))
- 결과

8.4 변이형 오토인코더를 사용한 이미지 생성
- GAN(; Generative Adversarial Networks)과 VAE(; Variational AutoEncoders)를 사용하여 소리, 음악 또는 텍스트의 잠재 공간을 만들 수 있다.
8.4.1 이미지의 잠재 공간에서 샘플링하기
- 이미지 생성 = 각 포인트가 실제와 같은 이미지로 매핑될 수 있는 저차원 잠재 공간(=벡터)의 표현을 만드는 것
- 생성자 (generator in GAN) or 디코더 (decoder in VAE) : 잠재 공간의 한 포인트를 입력으로 받아 이미지(픽셀의 그리드)를 출력하는 모듈
- VAE는 구조적인 잠재 공간을 학습하는 데 뛰어남
- GAN는 실제 같은 이미지를 만든다.
8.4.2 이미지 변형을 위한 개념 벡터
- 잠재 공간이나 임베딩 공간이 주어지면 이 공간의 어떤 방향은 원본 데이터의 흥미로운 변화를 인코딩한 축일 수 있다.
- 이런 벡터를 찾아내어 이미지를 잠재 공간에 투영해서 의미 있는 방향으로 이 표현을 이동한 후 이미지 공간으로 디코딩하여 복원하면 변형된 이미지를 얻을 수 있다.
- 개념 벡터 (concept vector) : 이미지 공간에서 독립적으로 변화가 일어나는 모든 차원
8.4.3 변형 오토인코더
- 오토인코더 (autoencoder) : 입력을 저차원 잠재 공간으로 인코딩한 다음 디코딩하여 복원하는 네트워크
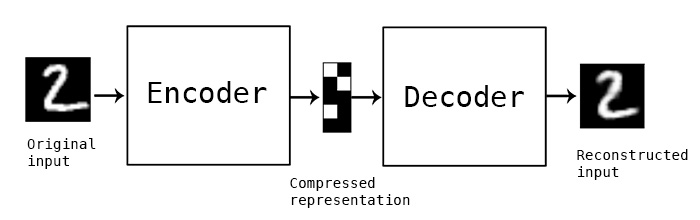
- 변이형 오토인코더 (VAE) : 딥러닝과 베이즈 추론의 아이디어를 혼합한 오토인코더의 최신 버전
- 오토인코더에 약간의 통계 기법을 추가하여 연속적이고 구조적인 잠재 공간을 학습
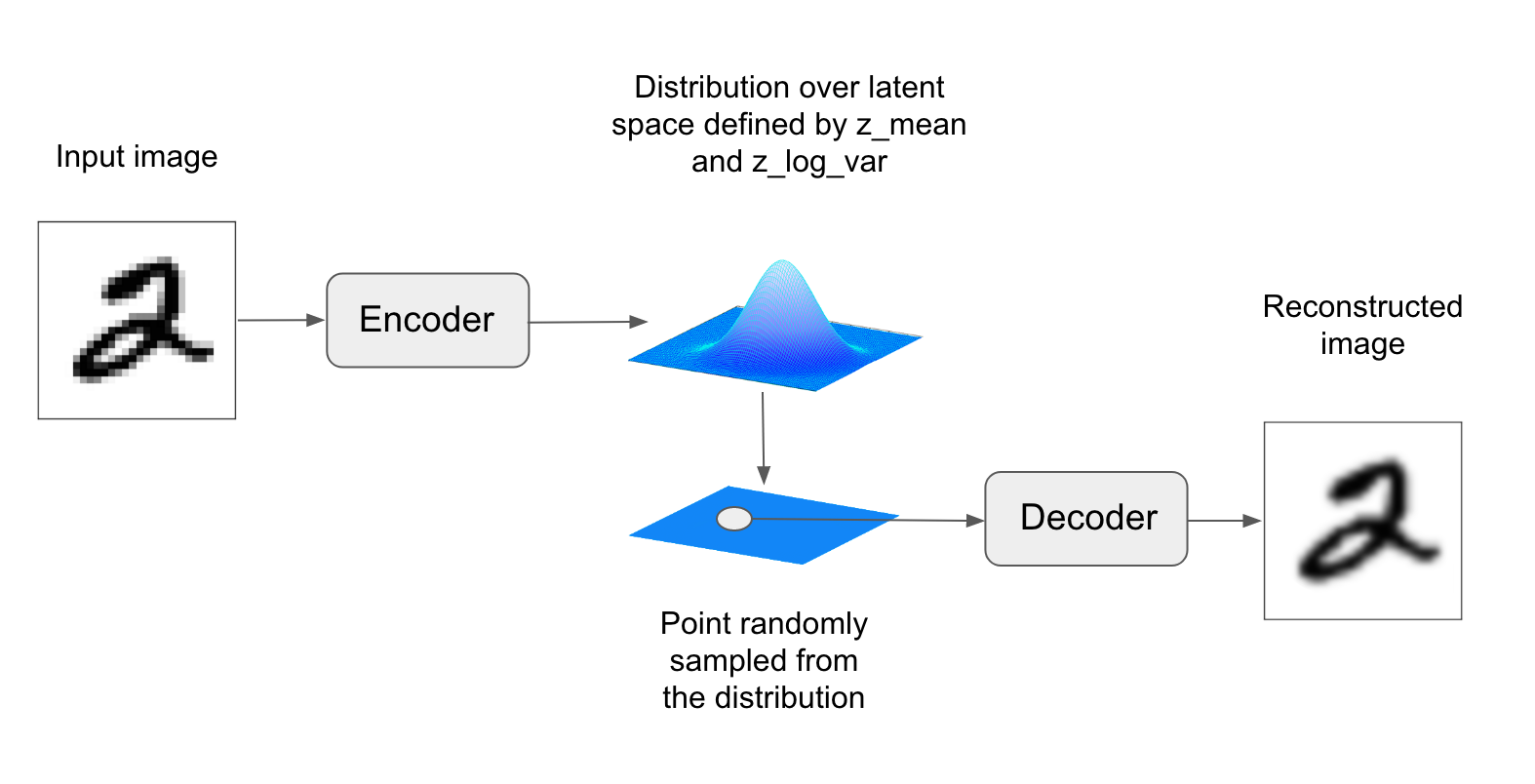
- VAE의 파라미터는 2개의 손실 함수로 훈련한다.
- 재구성 손실 (reconstruction loss) : 디코딩된 샘플이 원본 입력과 동일하도록 만듦
- 규제 손실 (regularization loss) : 잠재 공간을 잘 형성하고 훈련 데이터에 과대적합을 줄임
- 케라스의 VAE 구현
z_mean, z_log_var = encoder(input_img)
z = z_mean + exp(0.5 * z_log_var) * epsilon
reconstructed_img = decoder(z)
model = Model(input_img, reconstructed_img)
- 이 모델을 재구성 손실과 규제 손실을 사용하여 훈련한다.
- VAE 인코더 네트워크
- 이미지를 잠재 공간상 확률 분포 파라미터로 매핑
import tensorflow.keras
from tensorflow.keras import Input
from tensorflow.keras.layers import Conv2D, Dense, Flatten
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model
import numpy as np
img_shape = (28, 28, 1)
batch_size = 16
latent_dim = 2
input_img = Input(shape=img_shape)
x = Conv2D(32, 3, padding='same', activation='relu')(input_img)
x = Conv2D(64, 3, padding='same', activation='relu', strides=(2, 2))(x)
x = Conv2D(64, 3, padding='same', activation='relu')(x)
x = Conv2D(64, 3, padding='same', activation='relu')(x)
shape_before_flattening = K.int_shape(x)
x = Flatten()(x)
x = Dense(32, activation='relu')(x)
z_mean = Dense(latent_dim)(x)
z_log_var = Dense(latent_dim)(x)
- 잠재 공간 샘플링 함수
- 케라스의 Lambda : 임의의 함수 객체를 케라스의 층으로 만들어 준다.
from tensorflow.keras.layers import Lambda
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim),
mean=0., stddev=1.)
return z_mean + K.exp(0.5 * z_log_var) * epsilon
z = Lambda(sampling)([z_mean, z_log_var])
- 잠재 공간 포인트를 이미지로 매핑하는 VAE 디코더 네트워크
- int_shape() : 텐서의 크기를 파이썬 튜플로 반환하는 함수
- Conv2DTranspose 층 : 입력 값 사이에 0을 추가하여 출력을 업샘플링하는 전치 합성곱을 수행
from tensorflow.keras.layers import Reshape, Conv2DTranspose
decoder_input = Input(K.int_shape(z)[1:])
z = Dense(np.prod(shape_before_flattening[1:]),
activation='relu')(decoder_input) # 입력을 업샘플링
x = Reshape(shape_before_flattening[1:])(x)
x = Conv2DTranspose(32, 3,
padding='same',
activation='relu',
strides=(2, 2))(x)
x = Conv2D(1, 3,
padding='same',
activation='sigmoid')(x)
decoder = Model(decoder_input, x)
z_decoded = decoder(z)
에러 : ValueError: total size of new array must be unchanged, input_shape = [32], output_shape = [14, 14, 64]
댓글남기기