
[Spark] 아파치 카프카를 이용한 정형 스트리밍 예제
 [Spark The Definitive Guide - BIG DATA PROCESSING MADE SIMPLE] 책을 중심으로 스파크를 개인 공부를 위해 요약 및 정리해보았습니다.
[Spark The Definitive Guide - BIG DATA PROCESSING MADE SIMPLE] 책을 중심으로 스파크를 개인 공부를 위해 요약 및 정리해보았습니다.
다소 복잡한 설치 과정은 도커에 미리 이미지를 업로해 놓았습니다. 즉, 도커 이미지를 pull하면 바로 스파크를 사용할 수 있습니다.
도커 설치 및 활용하는 방법 : [Spark] 빅데이터와 아파치 스파크란 - 1.2 스파크 실행하기
도커 이미지 링크 : https://hub.docker.com/r/ingu627/hadoop
예제를 위한 데이터 링크 : FVBros/Spark-The-Definitive-Guide
예제에 대한 실행 언어는 파이썬 기반인 pyspark를 이용했습니다.
기본 실행 방법
1. 예제에 사용 될 데이터들은 도커 이미지 생성 후 spark-3.3.0 안의 하위 폴더 data를 생성 후, 이 폴더에 추가합니다.
1.1 데이터와 도커 설치 및 활용하는 방법은 위에 링크를 남겼습니다.
2. 터미널에서 pyspark을 입력해 프로그램을 시작합니다.
글에서 사용되는 파일 경로는 다를 수 있습니다.
1. 입력과 출력
- 이전 글에서는 스파크에서 스트림 처리 및 정형 스트리밍의 기초 개념들을 정리해보았다.
- 이번 글에서는 소스, 싱크 그리고 출력 모드가 정형 스트리밍에서 어떻게 동작하는지, 언제, 어디서, 어떻게 데이터가 유입되고 외부로 나가는지 살펴본다.
- 정형 스트리밍에서는 아파치 카프카, 파일 그리고 테스트 및 디버깅용 소스와 싱크를 지원한다.
1.1 데이터를 읽고 쓰는 장소(소스와 싱크)
파일 소스와 싱크
- 가장 간단한 소스는 실제에서 파일 소스로, 파케이, 텍스트, JSON, CSV 파일 등을 자주 사용한다.
- 스트리밍에서 파일 소스/싱크와 정적 파일 소스를 사용할 때 유일한 차이점은 트리거(Trigger) 시 읽을 파일 수를 결정할 수 있다는 것이다.
카프카 소스와 싱크
- 아파치 카프카(Apache Kafka)는 데이터 스트림을 위한 발행-구독(publish-scribe) 방식의 메시지 큐 기반 분산형 시스템이다.
- 카프카는 레코드의 스트림을 발행하고 구독하는 방식으로 사용한다.
- 발행된 메시지는 내결함성을 보장하는 저장소에 저장된다.
-
카프카를 분산형 버퍼로 생각할 수 있다.
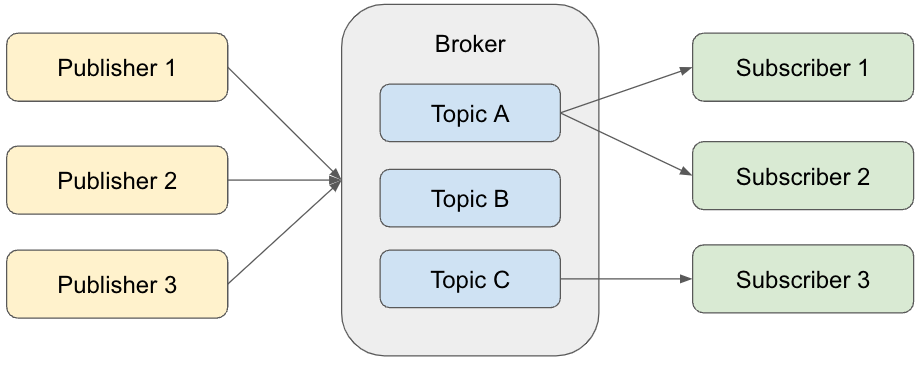
이미지출처 1 - 레코드(record)의 스트림은 토픽(topic)으로 불리는 카테고리에 저장한다.
- 카프카의 레코드는 키, 값, 타임스탬프로 구성된다.
- 레코드의 위치를 오프셋(offset)이라 한다.
- 토픽은 순서를 바꿀 수 없는 레코드로 구성된다.
- 카프카의 레코드는 키, 값, 타임스탬프로 구성된다.
- 데이터를 쓰는 동작을 발행(publish)이라 하며, 읽는 동작을 구독(subscribe)이라 한다.
- 스파크는 카프카에 저장된 스트림을 배치와 스트리밍 방식으로 읽어 DataFrame을 생성할 수 있다.
2. 카프카 소스에서 메시지 읽기
- 메시지를 읽기 위해 먼저 해야 할 일은 다음 옵션 중 하나를 선택하는 것이다.
- assign : 토픽뿐만 아니라 읽으려는 파티션까지 세밀하게 지정하는 옵션이다.
- ex.) JSON 문자열(
{"topicA":[0,1]}, "topicB":[2,4])
- ex.) JSON 문자열(
- subscribe : 토픽 목록을 지정해 여러 토픽을 구독하는 옵션이다.
- subscribePattern : 토픽 패턴을 지정해 여러 토픽을 구독하는 옵션이다.
- assign : 토픽뿐만 아니라 읽으려는 파티션까지 세밀하게 지정하는 옵션이다.
- 그 다음은 카프카 서비스에 접속할 수 있도록
kakfa.bootstrap.servers값을 지정하는 것이다. - 그 외 몇 가지 옵션을 더 설정해야 한다.
- startingOffsets 및 endingOffsets : 쿼리를 시작할 때 읽을 지점이다. 옵션값으로 earliest는 가장 작은 오프셋부터 읽으며 latest는 가장 큰 오프셋부터 읽는다.
- failOnDataLoss : 데이터 유실이 일어났을 때 쿼리를 중단할 것인지 지정한다. (default : True)
- maxOffsetPerTrigger : 특정 트리거 시점에 읽을 오프셋의 전체 개수이다.
-
카프카에서 메시지를 읽으려면 정형 스트리밍에서 다음 코드를 사용한다.
# topic1 구독 df1 = spark.readStream.format("kafka") \ .option("kafka.bootstrap.servers", "host1:port1, host2:port2") \ .option("subscribe", "topic1") \ .load() # 여러 개의 토픽 구독 df1 = spark.readStream.format("kafka") \ .option("kafka.bootstrap.servers", "host1:port1, host2:port2") \ .option("subscribe", "topic1, topic2") \ .load() # 패턴에 맞는 토픽 구독 df1 = spark.readStream.format("kafka") \ .option("kafka.bootstrap.servers", "host1:port1, host2:port2") \ .option("subscribe", "topic.*") \ .load()
- 카프카 소스의 각 로우는 다음과 같은 스키마를 가진다.
- 키 : binary
- 값 : binary
- 토픽 : string
- 패턴 : int
- 오프셋 : long
- 타임스탬프 : long
3. 카프카 싱크에 메시지 쓰기
-
카프카로 메시지를 발행하는 쿼리와 읽는 쿼리는 매우 비슷하다.
df1.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \ .writeStream \ .option("kafka.bootstrap.servers", "host1:port1, host2:port2") \ .option("checkpointLocation", "/to/HDFS-compatible/dir") \ .start() df1.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \ .writeStream \ .format("kafka") \ .option("kakfa.bootstrap.servers", "host1:port1, host2:port2") \ .option("checkpointLocation", "/to/HDFS-compatible/dir") \ .option("topic", "topic1") \ .start()
4. 테스트용 소스와 싱크
- 스파크는 스트리밍 쿼리의 prototype을 만들거나 debugging시 유용한 몇 가지 테스트용 소스와 싱크를 제공한다.
4.1 소켓 소스
- 데이터를 읽기 위한 호스트와 포트를 지정한 후, TCP 소켓을 통해 스트림 데이터를 전송할 수 있다.
- 스파크는 해당 주소에서 데이터를 읽기 위해 새로운 TCP 연결을 생성한다.
-
localhost:9999에서 데이터를 읽는 코드 예제는 다음과 같다.socketDF = spark.readStream.format("socket") \ .option("host", "localhost") \ .option("port", 9999).load() - 스파크 애플리케이션을 실행하면 9999 포트로 데이터를 전송할 수 있다.
-
소켓 소스는 입력 데이터 한 줄을 하나의 텍스트 문자열 로우로 구성한 테이블을 반환한다.
nc -lk 9999
4.2 콘솔 싱크
- 콘솔 싱크는 스트리밍 쿼리의 처리 결과를 콘솔로 출력할 때 사용한다.
-
기본적으로 append와 complete 출력 모드를 지원한다.
activityCounts.writeStream.format("console") \ .outputMode("complete") \ .start()
4.3 메모리 싱크
- 메모리 싱크는 스트리밍 시스템을 테스트하는 데 사용하는 소스이다.
- 드라이버에 데이터를 모은 후 대화형 쿼리가 가능한 메모리 테이블에 저장한다.
-
append와 complete 출력 모드를 지원한다.
activityCounts.writeStream.format("memory") \ .queryName("my_device_table")
5. 데이터 출력 방법 (출력 모드)
- 정형 스트리밍 지원하는 세 가지 출력모드는 다음과 같다.
- append 모드
- 새로운 로우가 결과 테이블에 추가되면 사용자가 명시한 트리거에 맞춰 싱크로 출력된다.
- 이벤트 시간과 워터마크를 append 모드와 함께 사용하면 최종 결과만 싱크로 출력한다.
- complete 모드
- 결과 테이블의 전체 상태를 싱크로 출력한다.
- 모든 데이터가 계속해서 변경될 수 있는 일부 상태 기반 데이터(stateful data)를 다룰 때 유용하다.
- update 모드
- 이전 출력 결과에서 변경된 로우만 싱크로 출력한다. 나머지는 complete 모드와 유사하다.
6. 데이터 출력 시점 (트리거)
- 트리거(trigger)를 설정하면 데이터를 싱크로 출력하는 시점을 제어할 수 있다.
- 정형 스트리밍에서는 보통 직전 트리거가 처리를 마치자마자 즉시 데이터를 출력한다.
-
현재는 처리 시간 기반의 주기형 트리거(periodic trigger)와 처리 단계를 수동으로 한 번만 실행할 수 있는 일회성 트리거(once trigger)를 제공한다.
# 처리 시간 기반 트리거 activityCounts.writeStream.trigger(processingTime='5 seconds') \ .format("console").outputMode("complete") \ .start() # 일회성 트리거 activityCounts.writeStream.trigger(once=True) \ .format("console").outputMode("complete") \ .start()
댓글남기기